II. HÀNH TRÌNH CỦA CHỮ VIỆT TRÊN MÁY VI TÍNH
Như đã nói, mục tiêu của phần này là mô tả quá trình hiển thị chữ Việt trên màn hình máy vi tính, từ “thuở ban đầu da diết ấy” cho đến thời hiện đại Vista, Linux… Nhiều yếu tố kỹ thuật công nghệ có thể đã quá lỗi thời, chỉ còn mang giá trị nghiên cứu và tham khảo. Tuy nhiên qua đó, chúng ta sẽ có một cái nhìn toàn cảnh về hành trình đầy gian nan nhưng không kém kỳ thú này.
1. MS-DOS – Vạn sự khởi đầu nan
 Máy vi tính bắt đầu xuất hiện ở Việt Nam vào những năm cuối của thập niên 1980’s. Phần lớn là dòng máy second-hand được trao tay dưới dạng viện trợ hoặc quà tặng cho các trường đại học, viện nghiên cứu, trung tâm quy hoạch thống kê…
Máy vi tính bắt đầu xuất hiện ở Việt Nam vào những năm cuối của thập niên 1980’s. Phần lớn là dòng máy second-hand được trao tay dưới dạng viện trợ hoặc quà tặng cho các trường đại học, viện nghiên cứu, trung tâm quy hoạch thống kê…
Nhu cầu hiển thị và gõ chữ Việt trên máy vi tính là yêu cầu bức thiết lúc bấy giờ. Mấy ai dễ quên được cái cảm xúc rạo rực ngồi chờ quá trình test BIOS của những chiếc máy XT, trước màn hình Monochrome đơn sắc. Khi dấu nhắc DOS thân quen hiện ra, những dòng lệnh thao tác lách cách và rồi… ENTER. Thế giới số buổi ban đầu đơn sơ như vậy đó.
Phần mềm đánh tiếng Việt đầu tiên tôi làm quen là VietStar, sử dụng kiểu gõ Telex với những tính năng đơn giản nhất. Dần dần, có thêm nhiều phần mềm khác ra đời để đáp ứng cho nhu cầu của người dùng trên nhiều lãnh vực. Khi hệ điều hành MS-Windows 3.1 bắt đầu khuynh đảo thị trường PC, chấm dứt kỷ nguyên MS-DOS, thì những phần mềm xử lý tiếng Việt sau được xem là đồng thống lãnh vương quốc DOS:
* VNI-Word của hãng VNI-Soft ở Mỹ
* BKED của Ô. Quách Tuấn Ngọc ở ĐHBK Hà nội
* VRES của Công ty Seatic ở Sài gòn
. . .
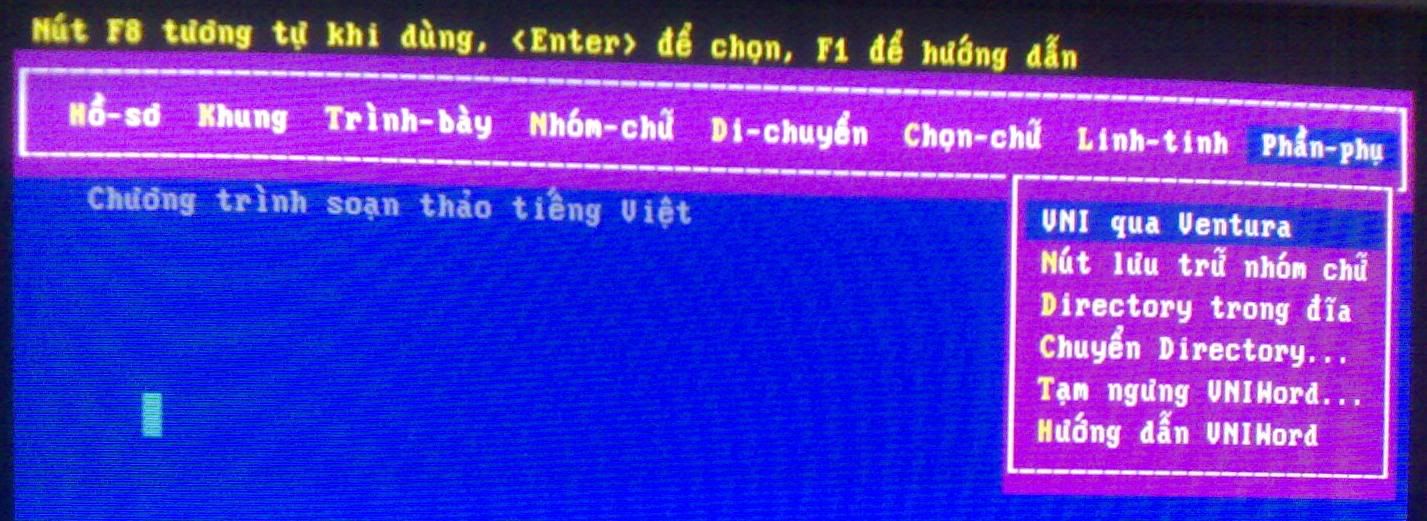 (Giao diện chương trình soạn thảo VniWord)
(Giao diện chương trình soạn thảo VniWord)Xét về nguyên lý hoạt động, có thể chia phần mềm xử lý tiếng Việt làm 2 nhóm chính: Xử lý độc lập và Thường trú.
a. Xử lý độc lập: Xây dựng môi trường soạn thảo riêng, với nhiều tính năng biên soạn chi tiết phục vụ cho từng nhu cầu khác nhau của người sử dụng. Kích thước chương trình tương đối lớn.
b. Thường trú: Với kích thước gọn nhẹ, nhóm ứng dụng này chỉ thực hiện 2 công việc chính là nạp lại font màn hình và chặn ngắt bàn phím để gõ chữ Việt, rồi cho thường trú trong bộ nhớ. Do đó, loại này có ưu điểm là chiếm ít bộ nhớ, được dùng kết hợp cùng với nhiều ứng dụng khác nhau.
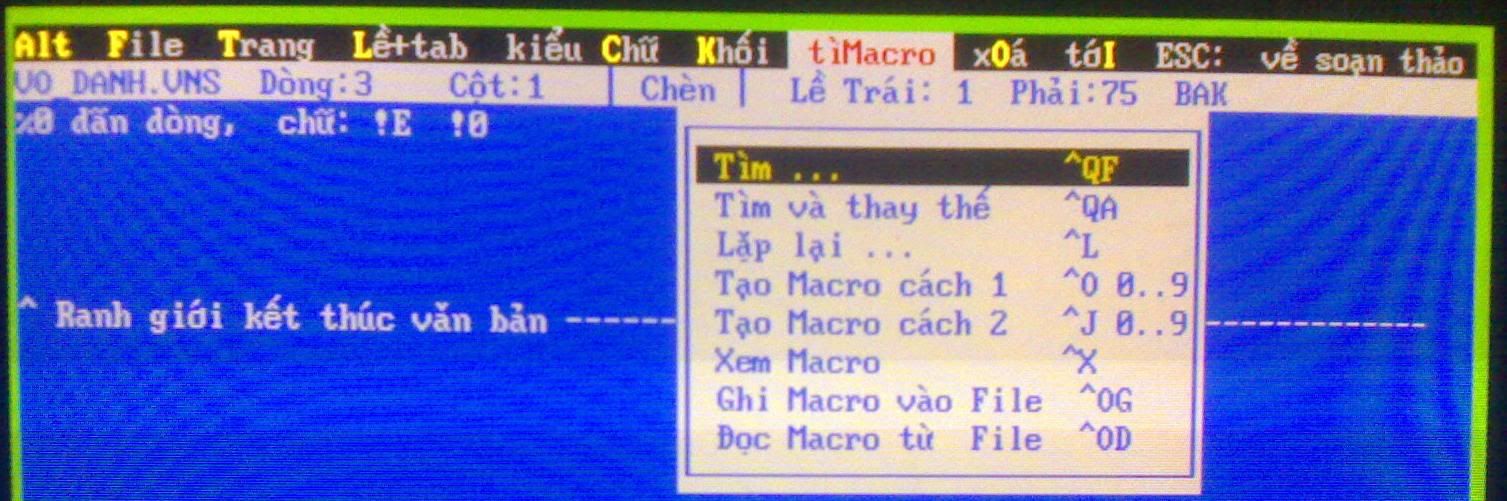 (BKED - chương trình soạn thảo dạng xử lý độc lập)
(BKED - chương trình soạn thảo dạng xử lý độc lập) (Menu giao diện của chương trình thường trú VRES - VRD.EXE)
(Menu giao diện của chương trình thường trú VRES - VRD.EXE)Thời ấy, người viết bài này vừa mới tập tễnh tự học lập trình nên cũng chịu khó tìm hiểu kỹ thuật xử lý chữ Việt. Kết quả là viết được một chương trình hợp ngữ (thông dịch bằng MASM) dạng thường trú để nạp font và gõ chữ Việt. Tuy khả năng xử lý bàn phím không thể so với VRD.EXE lúc bấy giờ, nhưng có thể gõ được chữ Việt ngay tại dấu nhắc MS-DOS, Norton Commander hay Sidekick... Mã nguồn tham khảo tại đây:
* VnKeyboard.asm
Ngoài ra, tôi còn viết một chương trình bằng Turbo Pascal để biên soạn font chữ cho 2 loại màn hình thông dụng lúc bấy giờ là EGA và VGA. Tải về để tham khảo tại đây:
* Mã nguồn: Font-Source
* Minh họa: Font-Demos
Xét về kiểu bỏ dấu Việt thì cũng có 2 nhóm: kiểu VNI và Telex
a. Kiểu VNI: Sử dụng các chữ số quy ước dấu. Do hãng VNI-Soft đề xướng
(1:sắc, 2:huyền, 3:hỏi, 4: ngã, 5:nặng, 6:mũ â-ê-ô, 7:móc ư-ơ, 8:ă, 9:đ-Đ)
b. Kiểu Telex: Dùng quy ước theo kiểu đánh tín hiệu MORSE của ngành bưu điện
(s: sắc, f: huyền, r: hỏi, x: ngã, j:nặng, aa: â - ee: ê - oo: ô, uw: ư - ow: ơ, aw - ă, dd: đ - DD: Đ)
Tất cả các phần mềm xử lý chữ Việt lúc này đều bị giới hạn rất khó chịu của bảng mã ASCII 8 bit. Theo kết cấu của bảng mã này, 127 ký tự chuẩn ban đầu là bất khả di dịch. Nếu muốn hiển thị toàn bộ chữ hoa và thường thì chữ Việt chiếm đến 134 ký tự, còn muốn “quên đi” việc hiển thị chữ in hoa thì chỉ cần 67 ký tự. Như vậy số lượng 128 ký tự trong phần mở rộng trở nên vô duyên vì muốn nói thiếu cũng được mà muốn nói thừa cũng chẳng sai!
Các phần mềm xử lý phải “hy sinh” một số trong 128 ký tự còn lại của phần mở rộng để mã hóa các chữ có dấu trong tiếng Việt. Việc quyết định nên “trảm” ký tự nào, giữ lại ký tự nào hình thành các bảng mã tiếng Việt khác nhau. Đây là điểm bất cập lớn nhất trong quá trình xử lý tiếng Việt trên máy vi tính. Một số phần mềm sử dụng giải pháp tổ hợp 2 byte để mã hóa, số khác dùng 1 byte. Ngay cả trong các phần mềm dùng 1 byte cũng không thống nhất với nhau về cách mã hóa. Do đó, “hồn ai nấy giữ” – văn bản do phần mềm nào soạn ra thì chỉ có nó mới hiệu chỉnh và xử lý tối ưu nhất.
Các phần mềm xử lý tiếng Việt đang chạy đua nhau để nâng cao hiệu năng sử dụng, thì cái đích đến bị dời bỏ. Dường như phiên bản Ms-DOS đã dừng ở con số 6.22, trước sự lấn lướt của giao diện đồ họa và khả năng đa nhiệm trong hệ điều hành MS Windows.
2. Ms Windows – Loạn N-Sứ quân vẫn chưa dứt
Trước uy thế quá mạnh mẽ của tiện ích soạn thảo văn bản Word và bảng tính điện tử Excel trong bộ phần mềm Ms Office, các phần mềm xử lý tiếng Việt từ bỏ ý định điên rồ là xây dựng lại môi trường soạn thảo độc lập. Họ đầu tư cho việc phát triển bộ gõ dấu và soạn font chữ Việt. Các “sứ quân” đình đám nhất trong triều đại Windows:
* VNI-Soft với bộ font chữ VNI- ra đời khá sớm chiếm được vị thế thượng phong cho người Việt hải ngoại lẫn quốc nội.
* ĐH Bách khoa Hà nội với bộ font ABC, mặc dù được hỗ trợ của TCVN 5712, nhưng ABC vẫn chỉ được dùng nhiều ở các tỉnh thành phía Bắc.
* Vietware và BK-HCM cùng chia sẻ thị trường các tỉnh phía Nam.
Tuy nhiên, việc sử dụng loại font chữ nào không nhất thiết phân bố theo vùng miền, mà cái chính có lẽ là do thói quen. Ban đầu ai đã trót dùng loại font nào thì sau đó rất ngại chuyển sang loại khác. Về sau, có thêm rất nhiều bộ gõ tiếng Việt nhỏ gọn, kèm theo tiện ích hỗ trợ chuyển đổi giữa các loại font chữ. Đơn cử vài phần mềm thông dụng nhất:
* UniKey của tác giả Phạm Kim Long
* VietKey của tác giả Đặng Minh Tuấn
* VPS của Hội Chuyên Gia Việt Nam (Vietnamese Professional Society)
* WinVNKey của nhóm TriChlor Software
...
Ngoài ra, Microsoft còn tích hợp một tiện ích bỏ dấu tiếng Việt ngay trong Windows. Ít người để ý và sử dụng công cụ này vì cách bỏ dấu không theo các kiểu truyền thống (VNI hoặc Telex). Kiểu bỏ dấu này quy ước như sau:
1:ă, 2:â, 3:ê, 4:ô, 5:huyền, 6:hỏi, 7:ngã, 8:sắc, 9:nặng, 0:đ, [:ư, ]:ơ
̃
Bất cập lớn nhất cũng vẫn là sự xung đột giữa các bảng mã (Loạn N-Sứ quân). Một thực trạng cười ra nước mắt là người sử dụng khi giao tiếp phải đóng gói theo bộ font của mình. Khổ nhất là các cô cậu sinh viên đang độ hầu bao xẹp lép, làm gì có tiền sắm máy in. Đến các dịch vụ in ấn nhỡ họ không có loại font mình dùng thì khổ. Về sau, các dịch vụ in ấn cũng chịu khó sưu tầm đủ tất cả các loại font thông dụng trên thị trường, dù phải trả giá là máy hoạt động có phần chậm hơn!
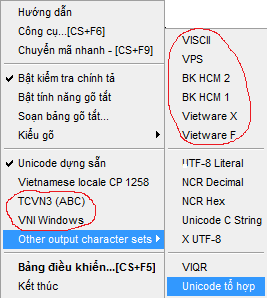 (Menu của bộ gõ UniKey vẫn hỗ trợ các bảng mã cũ)
(Menu của bộ gõ UniKey vẫn hỗ trợ các bảng mã cũ)Đoạn trường phát triển ứng dụng trên Ms-Windows cũng không kém phần trắc trở. Giao diện của các chương trình viết cho người Việt sử dụng cần phải hiển thị được chữ Việt. Font chữ hệ thống được chứa trong tập tin sserife.fon. Một số nhà phát triển đã can thiệp “thô” bằng cách chép đè tập tin này bởi tập tin đã sửa đổi theo bảng mã của mình. Điều này gây nên xung đột khi có nhiều chương trình sử dụng các loại bảng mã khác nhau. Người viết bài này đã tận mắt chứng kiến trường hợp một công ty mua phần mềm kế toán của một hãng tại Hà nội (sử dụng bảng mã ABC). Sau đó, lại mua thêm một phần mềm quản lý khác do một hãng ở Sài gòn (sử dụng bảng mã Vietware). Kết quả là 2 phần mềm này giành nhau một tập tin font hệ thống. Xài được chữ Việt cho phần mềm này thì phần mềm kia hiển thị “chữ miên” và ngược lại!
Thực ra, vấn đề này do lỗi từ phía 2 nhà phát triển phần mềm đã can thiệp thô bạo lên cấu hình hệ thống của Windows. Vẫn có cách nạp font chữ Việt cho giao diện trên Windows mà không cần đụng chạm đến tập tin font hệ thống. Giải pháp này được minh họa bằng một phần mềm viết bằng Delphi, sử dụng tập tin Vsserife.fon để nạp lên menu giao diện mà vẫn tôn trọng bản gốc sserife.fon của hệ thống. Xem phần mềm minh họa tại đây:
* Optics Mar.03
3. UNICODE – Theo dòng thác cách mạng toàn cầu
Có lẽ cuộc chiến giữa các bảng mã tiếng Việt sẽ bất phân thắng bại, vì mỗi loại đều có ưu / nhược điểm và một lượng người dùng tương đối. Người sử dụng tưởng chừng bế tắc trong thế phải chấp nhận sống chung với xung đột để đọc và viết chữ Quốc ngữ, thì dòng thác Unicode của thời đại số đã giải phóng cho họ.
Sự ra đời của bảng mã Unicode không chỉ giải quyết tranh chấp cho quá trình hiển thị chữ Việt, mà còn là vị cứu tinh cho nhiều giải pháp ngôn ngữ khác của cộng đồng quốc tế nói chung. Hiệp hội Unicode có trụ sở đặt tại Califonia (Hòa Kỳ), đã cho ra phiên bản đầu tiên (1.0) vào năm 1991. Cho đến thời điểm này phiên bản mới nhất là Unicode 5.1.0.
Ưu điểm lớn nhất là sự thống nhất trong bảng mã. Người Việt giờ đây không còn lo lắng về phiền toái do sự xung đột giữa các loại font chữ Việt.
Với không gian biểu diễn lên đến 1.114.112 (2^20 + 2^16) ký tự, hầu như tất cả các ngôn ngữ trên thế giới đều có thể được hiển thị đầy đủ, kể cả các ngôn ngữ tượng hình phức tạp như chữ Hán, Ả Rập, Thái Lan, Hàn Quốc…
Khoảng 100.000 mã đầu tiên đã được gán giá trị. 256 ký tự đầu tiên phù hợp tiêu chuẩn của ISO 8859-1 (là cách mã hóa phổ biến nhất trong thế giới La-tinh, do đó 128 ký tự đầu tiên được định danh theo bảng mã ASCII)
Không gian mã Unicode cho các ký tự được sắp xếp trong 17 mặt phẳng (plane). Mỗi mặt phẳng này có thể biểu diễn 65536 (2^16) ký tự.
- Mặt phẳng đầu tiên (plane 0) được gọi là Mặt phẳng đa ngôn ngữ căn bản (BMP – Basic MultiLanguage Plane). Đây là nơi chứa các ký tự căn bản cho hầu hết các ngôn ngữ phổ dụng trên thế giới, ngoài ra nó còn chứa một số ký hiệu đồ họa, tượng hình thông dụng. Phần lớn các ký tự trong mặt phẳng này phục vụ cho việc hiển thị các ngôn ngữ CJKV (Hán, Nhật, Hàn, Việt)
- Mặt phẳng thứ hai (plane 1) được gọi là Mặt phẳng đa ngôn ngữ bổ sung (SMP – Supplementary MultiLanguage Plane). Đây là nơi để biểu diễn ký tự trong các ngôn ngữ cổ hoặc ký hiệu trong âm nhạc.
…
- Mặt phẳng thứ 15 (plane 14) chứa các ký tự thẻ ngôn ngữ không được khuyến khích và một số ký hiệu lựa chọn biến thể.
- Hai mặt phẳng cuối (plane 15 và plane 16) để mở cho các tùy biến cá nhân.
Bảng mã Unicode được sắp xếp sao cho ít có sự trùng lắp nhất giữa các ký tự giống nhau trong mọi ngôn ngữ. Ví dụ, chữ é trong tiếng Pháp, tiếng Việt hay tiếng Czech… đều có chung một giá trị trong bảng mã là U+00E9. Điều này có thuận lợi là tiết kiệm không gian do không có trùng lắp, nhưng có điểm bất tiện là các ký tự trong bảng chữ cái của một ngôn ngữ không được xếp cạnh nhau, mà được phân bố rải rác.
Tháng 9/2001, Bộ Khoa học - Công nghệ & Môi trường (MOSTE) đã công bố tiêu chuẩn TCVN 6909:2001 (dựa trên nền tảng tiêu chuẩn ISO/ICE 10646 và Unicode 3.1). Đây được xem là tiêu chuẩn quốc gia của Việt Nam để mã hóa ký tự Unicode 16 bit.
Vấn đề xung đột giữa các bảng mã Việt đã không còn, nhưng giới lập trình phát triển ứng dụng có giao diện chữ Việt trên Windows vẫn phải đối mặt với nhiều thử thách. Nếu hệ thống xây dựng trên nền .NET thì giải pháp cho chữ Việt Unicode gần như hoàn chỉnh, không có gì đáng nói. Vấn đề hơi phiền phức cho các ứng dụng tương thích với nền Windows 32. Việc hiển thị mã Unicode gặp khó khăn vì đụng chạm đến phần tổ chức và khai báo kiểu dữ liệu cho chương trình. Ví dụ, với những phần mềm phát triển bằng Delphi trước kia sử dụng các bảng mã ABC, Vietware, VNI… thì đều có thể dùng kiểu dữ liệu chuỗi là ShortString. Khi muốn hiển thị theo chuẩn Unicode thì phải chuyển sang khai báo kiểu WideString. Một số hãng phát triển Component đã tung ra thị trường những gói hỗ trợ Unicode như: TntWare Delphi Unicode Controls, LMD ElPack, TMS Component Pack…
THAY CHO LỜI KẾT
Trong xu thế hội nhập toàn cầu, dùng tiếng Việt theo mã Unicode là điều không cần bàn cãi. Cho dù ảnh hưởng của quá khứ ABC, BK-HCM, VNI… vẫn còn khá nhiều trong các tài liệu, văn bản. Nhưng tất cả các phần mềm gõ dấu hiện nay đều cung cấp kèm theo miễn phí các tiện ích chuyển đổi mã tiếng Việt.
Khi bắt đầu soạn thảo một văn bản, tài liệu mới, hãy từ bỏ thói quen tìm kiếm font chữ ABC, VNI… Chỉ cần chọn 1 trong 2 font chữ căn bản nhất là Time New Roman hoặc Tahoma.
Nếu cần dùng các loại font đẹp cho nghệ thuật, bay bướm cho quảng cáo, trang trí… thì đã có các bộ font Unicode đủ kiểu xuất hiện ngày càng nhiều trên Internet. Giới thiệu một số địa chỉ:
* Bộ chữ Việt Nam Unicode
* Unicode Fonts For Windows
* Kho Font Unicode ĐH Kinh tế
* Font Đẹp
--------------
Hành trình chữ Việt trên PC (P.1)
.
 Tuyên ngôn Quốc tế Nhân quyền
Tuyên ngôn Quốc tế Nhân quyền Thế nào là Dân chủ
Thế nào là Dân chủ Từ Độc tài đến Dân chủ
Từ Độc tài đến Dân chủ Dự thảo Hiến pháp Việt Nam 2009
Dự thảo Hiến pháp Việt Nam 2009 DVD Sự Thật về Hồ Chí Minh
DVD Sự Thật về Hồ Chí Minh




 e*Calendar 7.5
e*Calendar 7.5 Testor ® 3.0
Testor ® 3.0 Optics Mar'06
Optics Mar'06 Sudoku Plus 1.0
Sudoku Plus 1.0 3D Rubik 1.8
3D Rubik 1.8 SCChess 2.0
SCChess 2.0 Couple 1.0
Couple 1.0
0 comments:
Post a Comment
Lời nói không mất tiền mua.
Làm ơn comment theo tinh thần tôn trọng sự thật và tự trọng bản thân!